Riding the AI Wave with Vector Databases: How they work (and why VCs love them)
Posted on April 14, 2023 by free ‐ 14 min read

Exploring the World of Vector Databases in 2023
In recent times, Vector Databases have been gaining popularity at an alarming rate due to their synergies with AI models like ChatGPT. Large Language Models (LLMs) like ChatGPT were trained on data that cut off in late 2021 which means they’re stuck in the past. They’re operating on a snapshot of the world that’s roughly 2 years out of date!
That’s still fine for many use cases, but what if you want to ask a question about something current like the weather or some latest news? You’re stuck (or they’ll pretend to know and hallucinate a fake answer for you).
Fortunately there is a workaround: You can BYOD (“Bring Your Own Data”) to provide these models with the specific information needed to answer your questions.
But now you have a new problem: How do you figure out what data to pass in when your dataset is big?
That’s where Vector Databases come in and what we’ll be examining in this post. But before we go into the technical details later, let’s divert our attention to take a look at how recent events happening in the Vector Database space are fueling their development and rapid growth.
Riding the AI Wave

The Venture Capital (VC) firms of the world have been busy throwing money at several Vector Database companies with Weaviate, a company built around an Open SourcePage product, closing a $16 million Series A round last month.
That may sound like a lot of dough, but there two other Vector Database startups that raised even bigger rounds with Chroma, a YC-backed Open SourcePage product, raising $18 million with just 1.2k GitHub stars and Pinecone, a proprietary Cloud-Only startup, raising a $28 million at an almost-unicorn valuation of $700 million.
With that much cash being splashed around it’s going to be interesting to see how these companies develop. How will they plan to differentiate themselves as more competition pops up? How long until we see big cloud companies like Amazon and Google entering this market too? Are these companies simply riding on the coattails of the success of giants like OpenAI, or is this the beginning of a new era of AI-first database technology?
I won’t be attempting to answer those questions in this post, but they’re helpful context to keep in mind as you dive into the technical details of how Vector Databases work, where they fit into the current database landscape, and how they’re being applied to augment AI models like ChatGPT.
What is a Vector Database?
A Vector Database stores a collection of “Vectors” which, in programming terms, are just “one-dimensional arrays of numbers”. Vectors are ubiquitous and used all the time in Machine Learning contexts, in any code that touches with 3D graphics, and a number of other places. (You can skip ahead if you’ve used vectors in any language before.)
They’re really just arrays of numbers though and the only real difference with a vanilla array is that the term “vector” implies tree things:
- The data is an array of floating point numbers (as opposed to integers, strings, etc.)
- They’re usually referred to by their dimension (how many numbers are in the array)
- For example, a
vector3is a 3-element array of floating point numbers. Avector4is (you guessed it!) a 4-element array of floating point numbers. Simple!
- For example, a
- There are special functions to operate on them like
normalize,dot,cross, etc.- These are just helpers though, and you can always just write your own functions to do the same thing.
The term “vector” itself comes from linear algebra, which is a branch of mathematics that deals primarily with matrices, tensors, and other array-like structures, but at the end of the day, they’re just fancy float arrays!
That does beg the question though: If they’re just float arrays, and since databases can already store arrays, do we really need a whole new database just for them?

Are VCs creating another bubble like they did with NoSQL databases?
Why are Vector Databases necessary?
Fortunately, the answer is simple: Performance.
Vector Databases are optimized for storing and performing operations on large amounts of vector data, often processing hundreds of millions of vectors per query, and doing it significantly faster than traditional databases are able to.
Here are some of the features that Vector Databases provide:
- Perform complex mathematical operations to filter and locate “nearby” vectors using clustering techniques like “Cosine Similarity” (which I’ll explain later)
- Provide specialized Vector indexes to make retrieval of data significantly faster and deterministic
- Store vectors in a way that makes them more compact, like by compressing and quantizing them, to keep as much data in memory as possible (further reducing load + query latency)
- Sharding data across multiple machines to handle large amounts of data (which many databases can do, but SQL databases in particular take more effort to scale out)
Relational vs Document vs Vector Databases

Relational Databases (SQL)
Examples include: PostgreSQL, MySQL, and MariaDB.
They use rows and columns to store data, similar to an Excel spreadsheet, and they support Vectors with extensions like pgvector. They’re not as trivially scalable as a dedicated Vector Database, but they’re much easier to deploy and manage due to their popularity with services like AWS RDS letting you spin up a production box in a few minutes.
Document Databases (often “NoSQL”)
MongoDB and CouchDB are the quintessential examples here, but technically Redis also sits in this space.
They tend to store data in JSON-like structures, called “documents”, that can are easy to work with, but they aren’t being used in the AI world very much today (most likely because they’re not as popular as SQL databases today). The exception is Redis which does have Vector support and is quite popular for in-memory use cases.
Vector Databases
These databases are very “niche” in the problem they solve. They are not general databases that you can use to build the back-end of your application. They only provide functionality to quickly locate multiple documents that contain similar text (this is done via a process known as “clustering” which we’ll discuss later).
That means that most applications will use a combination of a SQL database alongside a Vector database dedicated to provide document search and feed data into AI Models like OpenAI’s ChatGPT and other Large Language Models (LLMs). (This pattern is similar to other databases like ElasticSearch that provide important functionality for specific use cases.)
This is by no means an exhaustive list, but here are the most popular ones that I’ve seen people using:
- Weaviate (Open SourcePage)
- Milvus (Open SourcePage)
- FAISS (Open SourcePage)
- Pinecone (Cloud Only)
- Chroma (Open SourcePage)
- Qdrant (Open SourcePage)
For an up-to-date list of Vector Databases… Well, there isn’t one that I could find yet, so check back and I’ll add an Awesome List here to bookmark.
How do Vector Databases work with AI?
Language is complicated and our brains are amazing. In fact, we perform all sorts of complex operations automatically, without even thinking, and our brains are able to seamlessly understand the meaning behind certain words and phrases that we hear.
We’re so good at it that, until quite recently, computers have struggled to replicate even a fraction of this ability of ours. LLMs like GPT-3/ChatGPT are breakthrough models primarily because they excel at processing input and generating new, useful output (which feels very magical when it gets it right).
The problem is that these models have limited context. You can only fit in a few thousands words into them at a time. If you need to squeeze in more, tough luck! You’ve either got to fine-tune the model by training it on the data (which you can’t do with ChatGPT, only the older GPT-3 model) or, what is usually the better option, you need to extract only the relevant text for your specific prompt.
To give an example: If you want to have an answer to the question “What’s the best way to grill a steak?” you can’t just feed ChatGPT an entire cookbook all at once. These models can only understand 3000-6000 words at once, so you’ve got to be clever about which content you feed it.
Of course, a naive approach would be to just run a regex for “steak” and include those pages, but you’ll miss out on all the pages that talk about “beef”, “red meat”, “burgers”, and many other similarly related concepts. It’s easy as a human reading through the index to relate these items, but it’s very difficult to write a program to exhaustively map every related concept (without a significant time investment).
And that’s where embeddings come in. They’re a clever way to slice up the cookbook into smaller, more manageable chunks that can be fed into the limited context of a language model like ChatGPT.
What is an Embedding?
A “Text Embeddings”, or an “embedding” for short, is just an AI-specific term for “a bunch of vectors”, but where those vectors represent the semantic meaning behind how a word is being used in a specific context.
That’s a lot to unpack, so let me explain it in pieces.
(If you’re already familiar with embeddings, feel free to skip ahead. And if you’d like a more rigorous definition, check out this blog post.)
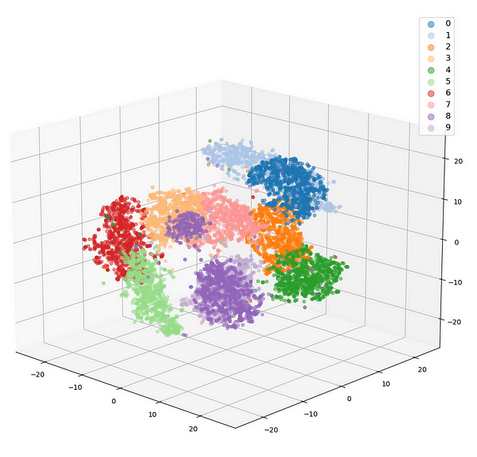
A visual representation of how embeddings are used to cluster data
Going back to our analogy: Beef, steak, and burger all have a similar “Semantic Meaning” to each other in the context of a recipe. They’re technically different words, but they all refer to the same thing: A piece of meat that you can cook and eat that comes from a cow.
Computers are dumb though – almost like they’re just rocks we tricked into doing math – and some really smart people at Google figured out how to build an AI model that could understand the association between different words by feeding it a large corpus of text.
In 2013 those smart Googlers published their model under the name “Word2Vec”. It was a huge breakthrough at the time (so much so that Google patented it) and it was one of the first big “breakthroughs” that took AI from “cool, but not useful” to “kinda maybe useful”.
But “kinda maybe useful” still wasn’t good enough for Google and they kept working on the problem until they published their next big paper called “Attention Is All You Need”, which became better known as laying the foundation for the Transformer Models that have since taken over the NLP scene.
What is a Transformer?
A Transformer is a type of neural network that’s designed to process sequential data, usually text but not always, and figure out which parts of it are the most important (they’re modeled after how human “attention” works).

NLP Goes Mainstream With Transformers
They’re important to be aware of because they’re the backbone of many of the most popular NLP models today, including generative models like GPT-3 and ChatGPT, as well as the modern Embeddings models that replace Word2Vec (models such as BERT (2018) and T5 (2020)).
(If you’ve ever wondered what the “T” in GPT-3 stands for… it’s “Transformer”. The full name being “Generative Pre-trained Transformer”!)
Both GPT and BERT are Transformers models that are good at understanding text, but they serve very different functions. While GPT is good at understanding and generating text, BERT is good at understanding the meaning behind the text and generating embeddings to represent that meaning. (Technically this is just one of many application of BERT, but it’s the one we’ll focus on for this blog post.)
They’re siblings, in a sense, and, when combined, they make a powerful duo!
How to use BERT to generate Embeddings
To get started, you’ll want to setup a Python environment and install the sentence-transformers library. Feel free to
follow along here in your own environment, but I’ll paste the outputs here for you to view also. (This is
basically just a modified version of the tutorial from
sentence-transformers.)
Setup Python Environment
python -m pip install virtualenv
virtualenv venv
source venv/bin/activate
python -m pip install --upgrade pip
Setup sentence-transformers
python -m pip install sentence-transformers
Then you can start using BERT to generate embeddings for your text!
Running Embeddings Generator Code
from sentence_transformers import SentenceTransformer
model = SentenceTransformer('all-MiniLM-L6-v2')
# The sentences that we wish to generate embeddings for
sentences = ['Here’s a cheffy way to cook steak that really makes the most of a good cut!',
'These burger patties are made with ground beef and an easy bread crumb mixture.',
'You can use any cut of beef for this sausage recipe, but a rib-eye is the best.']
# Generate the embeddings for our sentences
embeddings = model.encode(sentences)
# Print out the embeddings/vectors
for sentence, embedding in zip(sentences, embeddings):
print("Sentence:", sentence)
print("Embedding:", embedding)
print("")
Notice that I chose specific sentences without overlapping words, but with similar semantic meanings. (Steak, burgers, and beef)
The output of this program looks like this (each array contains 768 values):
$ python 1_print-embeddings.py
Sentence: Here’s a cheffy way to cook steak that really makes the most of a good cut!
Embedding: [-5.09411469e-02 -5.33863381e-02 -3.47178197e-03 -1.47095160e-03, ...]
Sentence: These burger patties are made with ground beef and an easy bread crumb mixture.
Embedding: [-2.56301872e-02 -9.13281962e-02 2.03740299e-02 -2.06439048e-02, ...]
Sentence: You can use any cut of beef for this recipe, but a rib-eye is the best.
Embedding: [ 1.14344181e-02 -3.60496975e-02 -2.92477775e-02 -2.06532031e-02, ...]
As you can see, this data is totally meaningless to a human! It’s really only useful when you feed into an algorithm like “Cosine Similarity” to measure the “distance” between both sentences. In this case, the distance between these sentences should be very small (closer to 1 than 0).
But the proof is in the pudding, so let’s try it out!
Running Cosine Similarity Code
Let’s tweak our example above to add in a question.
from sentence_transformers import SentenceTransformer, util
model = SentenceTransformer('all-MiniLM-L6-v2')
# The sentences that we wish to generate embeddings for
sentences = ['Here’s a cheffy way to cook steak that really makes the most of a good cut!',
'These burger patties are made with ground beef and an easy bread crumb mixture.',
'You can use any cut of beef for this sausage recipe, but a rib-eye is the best.']
# The question we want to ask
question = 'What is the best cut of beef for sausage?'
# Generate the embeddings for our sentences (note that we added `convert_to_tensor=True`)
sentence_embeddings = model.encode(sentences, convert_to_tensor=True)
question_embeddings = model.encode(question, convert_to_tensor=True)
# Compute cosine-similarities
cosine_scores = util.cos_sim(question_embeddings, sentence_embeddings)
print("Question: " + question)
# Output the pairs with their score
for i in range(len(sentence_embeddings)):
print("\t Score: {:.4f}\t \"{}\"".format(cosine_scores[0][i], sentences[i]))
The output should look like:
$ python 2_cosine-distance.py
Question: What is the best cut of beef for sausage?
Score: 0.541 "Here’s a cheffy way to cook steak that really makes the most of a good cut!"
Score: 0.365 "These burger patties are made with ground beef and an easy bread crumb mixture."
Score: 0.806 "You can use any cut of beef for this sausage recipe, but a rib-eye is the best."
As you can see, the sentence that is most similar to the question is the last one, which is exactly what we’d expect!
Using a Vector Database instead of a library
I’m going to stop short of showing you how to use a dedicated Vector Database since the scope of that is a bit larger than what I’d intended for this post. (This already is much longer than I’d planned for!)
To help nudge you in the right direction though here is a guide on how to use Chroma with Sentence Transformers which should get you pretty close.
If you would like me to write a follow-up post on how to setup and use a Vector Database for an embeddings search engine though, please drop me a line on the LunaBrain Discord with some of your thoughts! (It helps me a lot when writing to have feedback, especially when getting started with a new post.)
Conclusion
Vector Databases come into play when you need to store and query these embeddings quickly. They store data differently from traditional databases and provide indexes for efficient clustering and searching. They’re niche databases today, but we’re likely to see them grow to become household names like how ElasticSearch or Redis have become.
In the meantime, thank you so much for reading! I hope it was useful and that you learned something new – I certainly did while writing it!
Want to stay informed about the latest AI news?
Come join our Discord and share your thoughts with us. We’ve been building a community of AI hackers to help keep up with the insane pace of development happening right now in the AI world, and we’d love to have you join us!
