Using ChatGPT to clean scraped data, and how to handle any big document with ChatGPT
Posted on April 18, 2023 by forrest ‐ 10 min read

In this article we:
- Discuss cleaning up scraped webpage text, and what the existing solutions are
- Show that ChatGPT does a great job at cleaning up page text and providing other useful metrics simultaneously
- Show how to use ChatGPT to handle documents longer than its maximum token context length
Why we needed to scrape
When we discovered how powerful ChatGPT was, we decided to build a software security chat-bot so that people could ask it about vulnerabilities. Since vulnerabilities tend to be new and ChatGPT’s training data was old, we needed a way to get new information in front of ChatGPT. We planned to use a vector database to prompt-inject articles about vulnerabilities, and we decided to scrape them ahead of time so that the chat-bot would be fast enough. To learn more about how vector database’s work and how you can use them, read our vector blog post.
The problem with traditional scraping
Traditionally when you scrape a page, you end up with HTML. You can use a something like Puppeteer to use a real browser to make sure javascript loads, but you still end up with the HTML from the page. Now, ChatGPT understands HTML. The problem is that you’re always bumping up against a context length limit (and paying by the token, as well) with ChatGPT. Also, if we are adding in the vector database layer, the HTML junk will add a bunch of noise to the embeddings that will significantly impact performance.
There are some traditional, heuristic style scraping tools that will attempt to get the “main body” from the page, such as the Readability library by Mozilla. They work well for well known websites such as news sites, wikipedia, etc., but fall on their face with diverse and bespoke websites and blogs, which is what we need to parse. There may be better solutions out there than Readability that we haven’t tried, but really, nothing is going to beat the LLM for raw reasoning power.
Enter ChatGPT
First, we need the page text
Let’s get ChatGPT something to clean up.
An easy first step is to just scrape all the text that actually shows up on the page, ignoring HTML tags and anything hidden. In Puppeteer, that looks like this.
const normalized_content = await page.$eval('*', (el) => {
// skip everything that isn't an HTMLElement
if (!(el instanceof HTMLElement) ){
return ''
}
return el.innerText;
})
You could do something similar in any language with any scraping tool. Fully rendering JS was a must for us, though, and Puppeteer is good at that.
Now we have everything that’s showing on the page. Maybe a few hidden elements or other junk, but for the most part, these few lines will get you the page text. Unfortunately, this will get every button, sidebar, footer, etc, and it’s amazing how many of those there are.
For our purposes, all that non-article text is garbage that will pollute the vector space and the final prompt, too. Different pages will have different garbage, maybe in the middle, on the sidebar, the footer, the middle of the usable text, etc.
Clean it up
Since none of the existing tools are as good, let’s use ChatGPT.
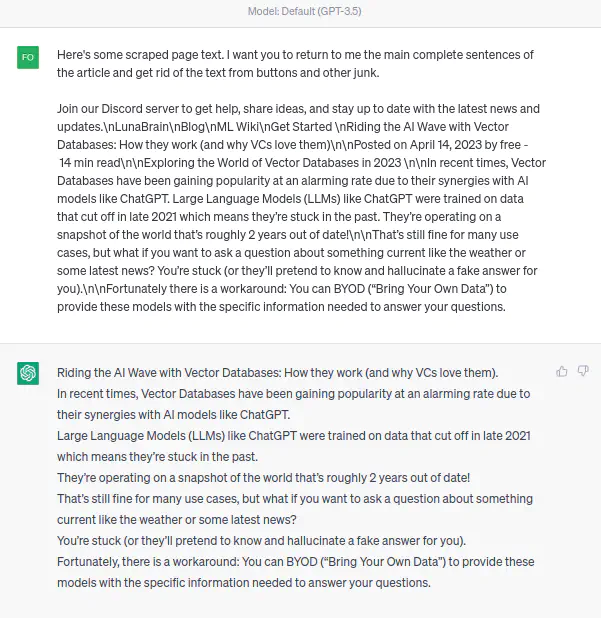
Here we can see that, of course, ChatGPT can clean up that text just as well as you can.
It won’t be the fastest, or the cheapest, but the result is incredibly good. Also, it can produce other metrics such as a short summary or some kind of “rank” relevance score as its cleaning the data. Very useful. For a complete working code example, you can follow along in this script which handles all the strategies explained in the rest of the article.
Let’s make a call to ChatGPT. Below is the template I wrote. It could probably be a lot shorter with some optimization, but this works fine.
The Prompt:
Below I’m going to give you a section of page contents that were scraped off of a webpage about a software vulnerability. Copy any sentences from the scraped page that might be useful into the template. The goal is to eliminate the useless parts of the scraped web page such as button text and headers, and go from scraped junk to a clean article. Omit anything that looks like a big block of code. It’s okay to stop in the middle of a sentence if that’s where the page contents ends. It’s also ok to return the body as an empty string if there is no useful text in the scraped section I gave you. Don’t omit any sentences from the scraped text, only remove things that look like text from buttons and footers and junk like that. Be sparing with what you omit. I want to see most of the content returned, minus all the one word sentences from buttons and so on.
The template for your response is: — BEGIN TEMPLATE — Body: [your cleaned up page text from the below scraped page here] Summary: [your one sentence summary of what this page is about, potentially refining the summary shown below. Give a meta-description of the page, not a direct summary of the contents. Ex: “Ruby-advisory-db page explaining mitigation techniques”] — END TEMPLATE —
And here are the scraped page contents: — BEGIN SCRAPED PAGE CONTENTS — {page_content} — END SCRAPED PAGE CONTENTS —
Here is the existing summary from the contents higher up on the page, if there is one — BEGIN EXISTING SUMMARY — {existing_summary} — END EXISTING SUMMARY —
This is the last couple of sentences of a section of the page you previously processed. I’m showing you so that you can try to make your new section mesh grammatically with the last word of this previously processed text, as we will be adding your new “body” response onto the end of it. If it’s empty then nevermind and just start fresh. — BEGIN PREVIOUS BODY — {existing_body} — END PREVIOUS BODY —
That’s a huge prompt, but it does work quite reliably. You could probably slim this down quite a bit and still get a good result. Note that we give it a strict template for its output so that we can regex out the multiple fields. This is also helpful to keep ChatGPT from saying sentences we can’t use like “Sure, let me help you with that.” before it gives its response. It’s very polite, but we can’t parse polite.
The power of ChatGPT to provide arbitrary metrics is extremely useful
Note that we also ask for a summary of the page, because that’s going to help us search through these documents later. In another experiment, we had GPT-4 generate a question it wanted an answer to, such as “When was the Log4Shell vulnerability first published by LunaSec?”, and then passed that question over to a similar ChatGPT prompt. This time, we asked it for the answer to the question, a summary , and also a score from 0 to 100 of how well the page answered the question. We noted that it did an incredibly good job at subjectively rating the pages on their usefulness.
A note on LangChain and Python
To render this template, parse the response, and handle the actual calls to ChatGPT, we use LangChain. You could really use just about any library in any language to do this, if you’re not a fan of python. There’s a pretty good Javascript implementation of LangChain, too. OpenAI libraries are coming out in just about every popular language now, or you could easily write your own client. Nothing in here is very complicated or qualifies as real “machine learning”. To be honest, sometimes it doesn’t even feel like programming. It’s that easy.
Looping
Because of the token limit of 4096 (which tends to be around 16000 chars), pages are often too long to pass in all at once. Note that in the prompt, we can pass in the end of a previous section, and a previous summary. That’s so that we can loop ChatGPT over chunks of the document, and then in the end we just concat them all together.
There is a choice between calling ChatGPT in parallel (faster) or in sequence (slower), and in this case we chose to go in sequence, map-reduce style. This is so that we can have ChatGPT stitch the chunks together in a grammatically correct way. Otherwise, the chunk boundaries might get a bit garbled. In other words, we are chunking the scraped web page contents into ChatGPT, with a little bit of an overlapping window where the last result feeds into the next query. This method also helps refine the summary we asked ChatGPT to give us as it reads down the page, adding new information without losing context from higher up the page.
How to calculate your token budget
Going over the 4096 token limit in one request will break the entire flow. The token limit is a bit like playing blackjack. Ideally we will nearly fill it up, but it’s better to be under than over.
Note that we have to leave space for the prompt, the passed in page contents, the snippets from previous loops, and ChatGPT’s response. We know that in this case the output will be roughly the same size or smaller than the input size, so if we split our roughly 4000 token budget in half, that leaves us 2000 tokens for input. Since our prompt takes us about 500 tokens, let’s just use a size of 1500 as our splitter. You can use OpenAI’s tokenizer to see how many tokens your prompt uses. The visualization is nice as well and gives you a feel for how tokens work.
To split the documents in an intelligent way, we are using Langchain’s TokenTextSplitter to give us an array of
chunks of the proper size. There are various splitters that will try to split on a complete sentence just before the
token limit reached, and so on. This simple splitter seemed to work fine, though.
from langchain.text_splitter import TokenTextSplitter
content_splitter = TokenTextSplitter(chunk_size=1500, chunk_overlap=0)
split_content = content_splitter.split_text(page_content)
We do a similar thing to get the last sentence or so from the previous loop, if there was one, so that ChatGPT can stitch them together without grammar issues.
How much does it cost
Well, we scraped about 10,000 pages before we hit our quota and needed to increase it. That took around 24 hours and cost around $100. Slow, expensive, but extremely effective. If you’re going to do this, make sure to have a high OpenAI quota first, since that takes a few days and a human approval.
Other uses
This approach can be used for just about any long-form of text that exceeds the token limit. Most of the code we wrote was just strategies to split up and combine chunks so as not to exceed the token limit. The same strategy could probably be used to translate entire books, or just about any other language task you can imagine that will use more than 4096 tokens.
Other cool technologies out there
WebGPT
OpenAI actually specifically trained an LLM for browsing the web, and no doubt it doesn’t a better job than anything we talked about here if what you really want to do is just have an AI read the web. It can follow links and browse the internet like a human. If I had to guess, I’d say something like this is behind the new Bing chat-bot. Unfortunately, it’s not public and there is no API to use it. OpenAI, huh?
LMQL
LMQL is a new DSL for prompting LLMs and parsing results. It also does an extremely clever thing called “token-level prediction masks” which helps to deal with the off-prompt responses that you often get with langchain. Something like this is clearly the future for these more complex prompts, and it really exposes my (LangChain’s) string templating and Regex parsing for the spaghetti it is. Hopefully we’ll have a full post up about LMQL soon.
Conclusion
Thanks for reading and be sure to join us in our machine learning discord if you’d like to chat about this stuff. We’ve managed to get some pretty smart folks in there. You may also want to check out LunaBrain, a framework we wrote to make all of this stuff a lot easier. It’ll be getting some better docs and examples over the next week or two.